
Vượt trội GPT-4o với Llama 3 8B: Điều chỉnh tinh chỉnh theo miền cụ thể cho RAG
Mục lục:
- Giới thiệu
- Giải pháp toàn diện với mô hình ngôn ngữ lớn mã nguồn mở
- Tại sao cần điều chỉnh tinh chỉnh?
- Kết quả đánh giá
- Ví dụ đánh giá
- Kết luận
1. Giới thiệu
Nhiều khách hàng của chúng tôi nhận thấy rằng mặc dù các mô hình mã nguồn đóng từ OpenAI và Anthropic hoạt động tốt đối với các tác vụ chung, nhưng chúng không đủ hiệu quả để áp dụng vào hoạt động kinh doanh cốt lõi, nơi mà hiệu suất tác vụ chuyên biệt, chi phí vận hành quy mô lớn và quyền sở hữu mô hình trở nên quan trọng. Bài viết này chia sẻ cách chúng tôi giúp khách hàng sử dụng AI để tự động hóa các tác vụ độc quyền này với các mô hình mã nguồn mở được tinh chỉnh. Chất lượng cao hơn này cho phép khách hàng mở khóa khả năng tự động hóa không có sẵn với các mô hình chung, đồng thời chạy nhanh hơn 13 lần và rẻ hơn 33 lần so với GPT-4o, và nằm trong một mô hình thuộc sở hữu mà họ có thể sử dụng với dữ liệu nhạy cảm, bên trong tường lửa của họ.
2. Giải pháp toàn diện với mô hình ngôn ngữ lớn mã nguồn mở
Bài viết này mô tả một giải pháp toàn diện chỉ sử dụng các Mô hình Ngôn ngữ Lớn (LLM) mã nguồn mở để:
Tạo tập dữ liệu Câu hỏi & Câu trả lời để tinh chỉnh các mô hình nhỏ hơn và nhanh hơn:
- Trích xuất dữ liệu từ tài liệu và sử dụng Llama 3 8B với tốc độ trên 1000 token/giây để tạo hàng nghìn cặp Câu hỏi & Câu trả lời.
- Tinh chỉnh Llama 3 70B để lọc các cặp Câu hỏi & Câu trả lời chất lượng thấp và chạy bước kiểm soát chất lượng tập dữ liệu với tốc độ trên 570 token/giây.
Xây dựng ứng dụng RAG (Retrieval Augmented Generation - Tạo nội dung được tăng cường bằng truy xuất):
- Tinh chỉnh các embedding mã nguồn mở (như Microsoft’s E5 Large V2) để tạo đường dẫn truy xuất tốc độ cao và chính xác, vượt trội so với embedding hàng đầu của OpenAI: Text Embedding 3 Large.
- Tinh chỉnh các LLM mã nguồn mở (như Llama 3 8B) để tạo câu trả lời từ ngữ cảnh được truy xuất với tốc độ 1000 token/giây và chính xác hơn so với GPT4-o hàng đầu của OpenAI.
- Đánh giá câu trả lời RAG bằng Llama 3.1 405B, mô hình đã được chứng minh là cung cấp hiệu suất đánh giá hàng đầu.
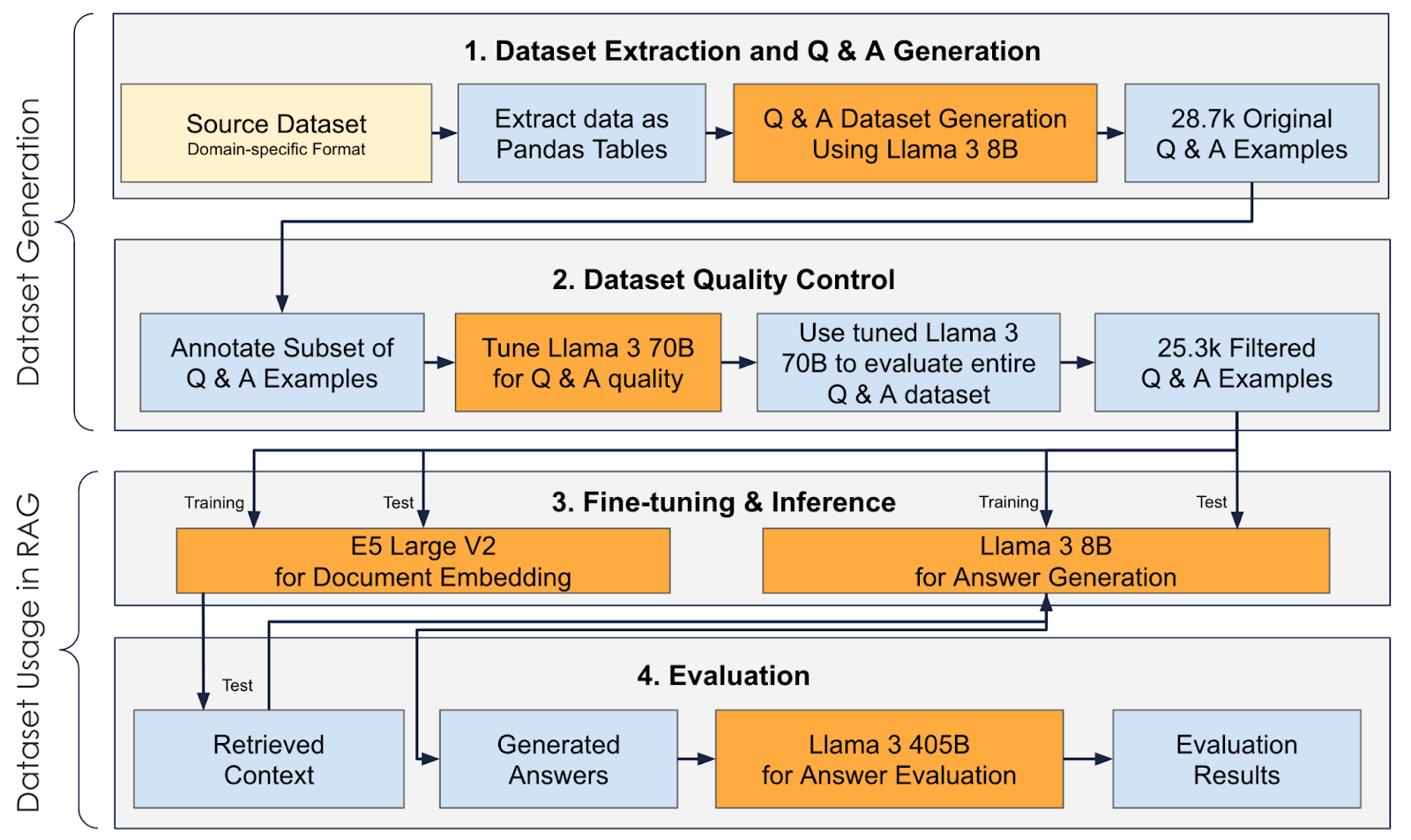
Hình trên mô tả quá trình toàn diện từ tạo tập dữ liệu đến sử dụng trong RAG.
3. Tại sao cần điều chỉnh tinh chỉnh?
Điều chỉnh tinh chỉnh có thể không cần thiết đối với nhiều trường hợp sử dụng mà cơ sở kiến thức không chứa thuật ngữ chuyên ngành. Tuy nhiên, khi có thuật ngữ chuyên ngành, embedding và LLM có thể không biết cách mã hóa chúng ngay lập tức và điều chỉnh tinh chỉnh có thể giúp ích. Hơn nữa, việc tinh chỉnh các mô hình nhỏ hơn có thể đạt được độ chính xác cao hơn so với các mô hình lớn hơn nhiều trong khi cung cấp năng suất cao hơn (khả năng xử lý nhiều câu hỏi hơn mỗi giây).
4. Kết quả đánh giá
Các kết quả sau so sánh hiệu suất của các mô hình embedding có và không được tinh chỉnh trên một tập dữ liệu chuyên ngành chứa thuật ngữ an ninh mạng:
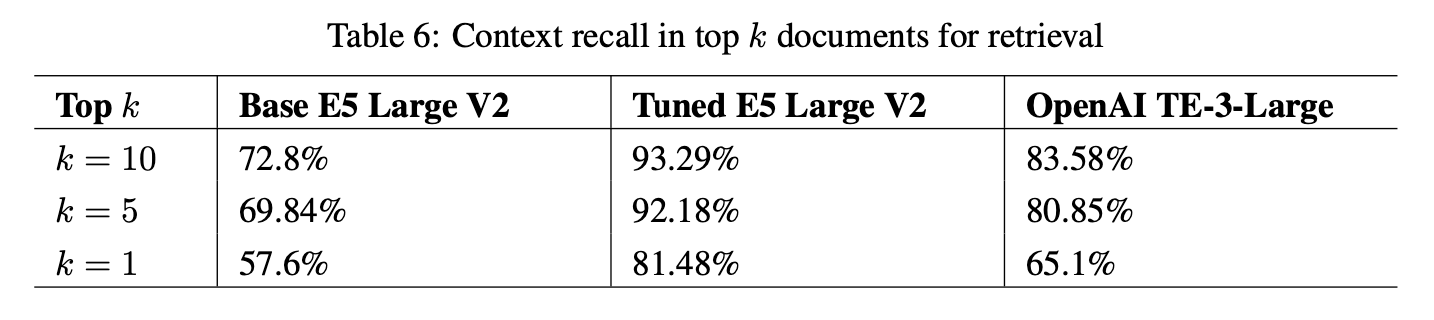
Thu hồi ngữ cảnh đề cập đến khả năng của các mô hình trong việc mã hóa tài liệu sao cho các tài liệu có liên quan được trả về trong kết quả top k cho một câu hỏi nhất định.
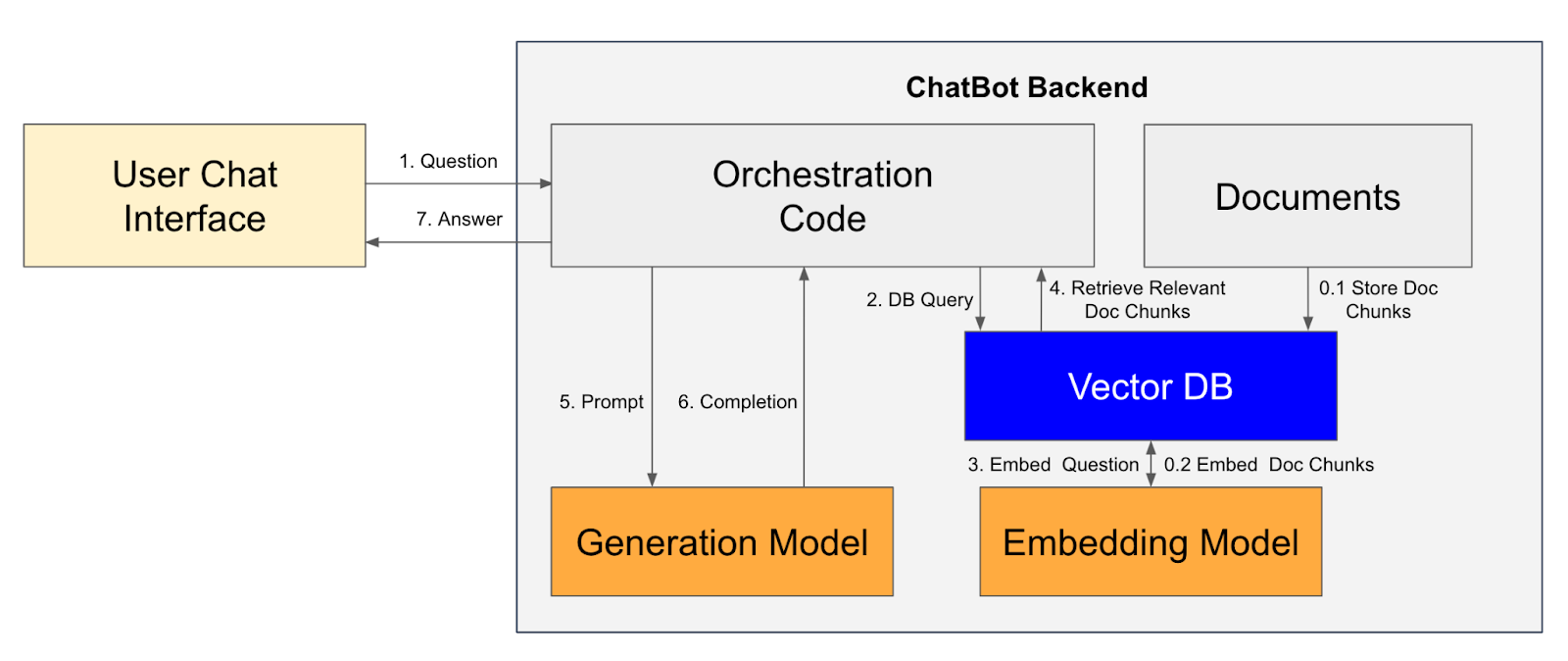
Đường dẫn RAG kết hợp các mô hình embedding để truy xuất và LLM để tạo câu trả lời bằng cách sử dụng ngữ cảnh được truy xuất. Các bước trong đường dẫn RAG, hỗ trợ chatbot, được mô tả trong sơ đồ sau:
Bảng sau đây trình bày kết quả đối với các cấu hình khác nhau của đường dẫn RAG được sử dụng trên tập dữ liệu an ninh mạng. Cột đầu tiên sử dụng các mô hình hàng đầu từ OpenAI, chẳng hạn như embedding Text Embedding 3 Large (TE-3-L) và LLM GPT-4o. Các cột còn lại có các kết hợp của mô hình không được tinh chỉnh ("Base") và mô hình được "Tinh chỉnh" với lý do (bao gồm cả quá trình "suy nghĩ" cùng với "câu trả lời" cho một "câu hỏi"). "Emb" đề cập đến embedding E5 V2 Large và "Gen" đề cập đến Llama 3 8B.
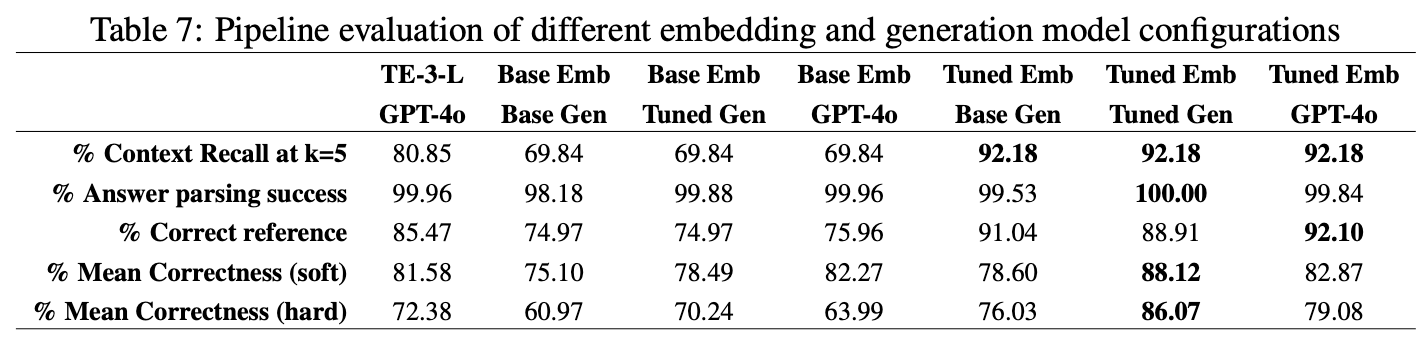
Rõ ràng từ các kết quả trên, việc tinh chỉnh cả mô hình embedding và mô hình tạo ra độ chính xác cao nhất trong việc truy xuất và tạo kết quả. Cần lưu ý rằng các mô hình được tinh chỉnh nhỏ hơn nhiều so với các mô hình OpenAI mà chúng ta đang so sánh, mang lại lợi thế về năng suất ngoài độ chính xác. Trong bảng trên:
- "Thành công phân tích câu trả lời" đề cập đến khả năng của LLM trong việc tạo ra câu trả lời và tài liệu tham khảo theo định dạng bắt buộc để phân tích downstream. Lưu ý rằng việc tinh chỉnh LLM tạo ra sự khớp hoàn hảo với định dạng yêu cầu.
- "Tài liệu tham khảo chính xác" đề cập đến khả năng của mô hình trong việc đưa ra tài liệu tham khảo chính xác đến tài liệu chứa câu trả lời chính xác. GPT-4o hoạt động tốt hơn một chút ở đây với sự trợ giúp của embedding mã nguồn mở được tinh chỉnh.
- "Độ chính xác trung bình (mềm)" đề cập đến độ chính xác của mô hình, do Llama 3 405 xác định, đồng thời đưa ra các nhượng bộ cho sự thất bại của thành phần truy xuất/embedding của đường dẫn. Nếu tài liệu có liên quan đến câu hỏi không được truy xuất, thì mô hình phải tuyên bố không biết câu trả lời. Sự kết hợp embedding và tạo được tinh chỉnh hoạt động tốt nhất.
- "Độ chính xác trung bình (cứng)" đề cập đến độ chính xác của mô hình, do LLama 3 405 xác định, bất kể thành phần truy xuất/embedding của đường dẫn có trả về ngữ cảnh không liên quan hay không. Sự kết hợp embedding và tạo được tinh chỉnh hoạt động tốt nhất. Mặc dù các mô hình được tinh chỉnh chưa thấy các câu hỏi được sử dụng trong quá trình đánh giá (thuộc tập dữ liệu giữ lại), nhưng chúng rất quen thuộc với cơ sở kiến thức của các tài liệu và điều đó mang lại cho chúng lợi thế trong việc trả lời câu hỏi một cách chính xác.
5. Ví dụ đánh giá
Sau đây là một ví dụ về đánh giá được thực hiện bởi Llama 3 405B, được nhắc nhở để cung cấp điểm số và lý do đưa ra điểm số đó:

Trong ví dụ trên, tất cả các embedding đều tìm thấy tài liệu chính xác (d*) trong thành phần truy xuất và xếp hạng nó trong top 3. GPT-4o tạo ra câu trả lời kém chính xác hơn so với Llama 3 8B được tinh chỉnh. Giống như GPT-4o, ngay cả Llama 3 8B cơ bản cũng không đề cập đến việc "kiểm thử và gỡ lỗi" là mục đích của khóa đăng ký 'Office Test'. Điều đó là bất chấp thực tế là tên của khóa ngụ ý mục đích và mục đích được nêu rõ trong tài liệu. Điều đó cho thấy rằng việc tinh chỉnh mô hình tạo ra với các lý do có thể giúp cải thiện khả năng lập luận.
6. Kết luận
Tóm lại, các mô hình mã nguồn mở nhỏ hơn có thể được tận dụng và tinh chỉnh để vượt trội hơn các mô hình độc quyền hàng đầu, cả về tốc độ và độ chính xác.
Để biết thêm chi tiết về thiết lập các kết quả trên, vui lòng tham khảo bài báo sau: AttackQA: Phát triển và áp dụng tập dữ liệu để hỗ trợ hoạt động an ninh mạng bằng cách sử dụng LLM mã nguồn mở và được tinh chỉnh.
0 comments Blogger 0 Facebook
Đăng nhận xét