
Mục lục
- Giới thiệu
- Thách thức trong hệ thống phục vụ LLM
- FastSwitch: Giải pháp đột phá
- Ba tối ưu hóa chính của FastSwitch
- Đánh giá hiệu suất
- Kết luận
1. Giới thiệu
Mô hình ngôn ngữ lớn (LLM) đã cách mạng hóa các ứng dụng trí tuệ nhân tạo (AI), hỗ trợ các tác vụ như dịch ngôn ngữ, trợ lý ảo và tạo mã. Tuy nhiên, việc cung cấp dịch vụ chất lượng cao cho nhiều người dùng đồng thời đặt ra những thách thức đáng kể về quản lý tài nguyên, đặc biệt là GPU có băng thông bộ nhớ cao. Việc phân bổ hiệu quả các tài nguyên hạn chế này là rất quan trọng để đáp ứng các mục tiêu mức độ dịch vụ (SLO) cho các chỉ số nhạy cảm với thời gian, đảm bảo hệ thống có thể phục vụ nhiều người dùng hơn mà không ảnh hưởng đến hiệu suất.
2. Thách thức trong hệ thống phục vụ LLM
Một vấn đề dai dẳng trong các hệ thống phục vụ LLM là đạt được sự phân phối tài nguyên công bằng đồng thời duy trì hiệu quả. Các hệ thống hiện tại thường ưu tiên thông lượng, bỏ qua các yêu cầu về tính công bằng như cân bằng độ trễ giữa các người dùng. Các cơ chế lập lịch ưu tiên, điều chỉnh động ưu tiên yêu cầu, giải quyết vấn đề này. Tuy nhiên, các cơ chế này lại dẫn đến chi phí chuyển đổi ngữ cảnh, chẳng hạn như thời gian nhàn rỗi của GPU và sử dụng I/O không hiệu quả, làm giảm các chỉ số hiệu suất chính như Thời gian đến Token đầu tiên (TTFT) và Thời gian giữa các Token (TBT). Ví dụ, thời gian ngừng hoạt động do ưu tiên trong các kịch bản áp lực cao có thể lên tới 59,9% độ trễ P99, dẫn đến sự suy giảm đáng kể trải nghiệm người dùng.

Các giải pháp hiện tại, chẳng hạn như vLLM, dựa vào quản lý bộ nhớ dựa trên phân trang để giải quyết các hạn chế về bộ nhớ GPU bằng cách hoán đổi dữ liệu giữa bộ nhớ GPU và CPU. Mặc dù các phương pháp này cải thiện thông lượng, nhưng chúng vẫn gặp phải những hạn chế. Các vấn đề như phân bổ bộ nhớ bị phân mảnh, sử dụng băng thông I/O thấp và truyền dữ liệu dư thừa trong các cuộc hội thoại nhiều lượt vẫn tồn tại, làm suy yếu hiệu quả của chúng. Ví dụ, kích thước khối cố định 16 token của vLLM dẫn đến độ chi tiết không tối ưu, làm giảm hiệu quả băng thông PCIe và tăng độ trễ trong quá trình chuyển đổi ngữ cảnh ưu tiên.
3. FastSwitch: Giải pháp đột phá
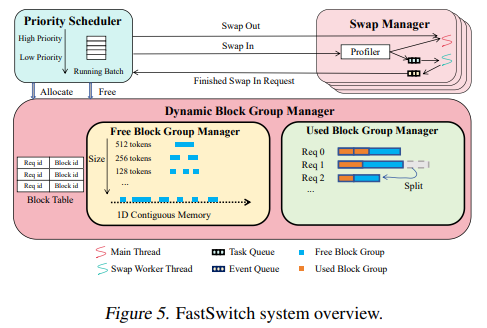
Các nhà nghiên cứu từ Đại học Purdue, Viện Thượng Hải Kỳ Chí và Đại học Thanh Hoa đã phát triển FastSwitch, một hệ thống phục vụ LLM có nhận thức về tính công bằng giải quyết sự không hiệu quả trong việc chuyển đổi ngữ cảnh. FastSwitch giới thiệu ba tối ưu hóa cốt lõi: trình quản lý nhóm khối động, trình quản lý hoán đổi đa luồng và cơ chế tái sử dụng bộ nhớ cache KV.
4. Ba tối ưu hóa chính của FastSwitch
- Trình quản lý nhóm khối động: Tối ưu hóa việc phân bổ bộ nhớ bằng cách nhóm các khối liền kề, tăng độ chi tiết truyền. Phương pháp này giảm độ trễ lên đến 3,11 lần so với các phương pháp hiện có.
- Trình quản lý hoán đổi đa luồng: Nâng cao hiệu quả tạo token bằng cách cho phép hoán đổi không đồng bộ, giảm thiểu thời gian nhàn rỗi của GPU. Nó tích hợp đồng bộ chi tiết để tránh xung đột giữa các yêu cầu đang diễn ra và các yêu cầu mới, đảm bảo hoạt động liền mạch trong quá trình chồng chéo.
- Cơ chế tái sử dụng bộ nhớ cache KV: Giữ lại dữ liệu hợp lệ một phần trong bộ nhớ CPU, giảm độ trễ ưu tiên bằng cách tránh truyền dữ liệu bộ nhớ cache KV dư thừa.

5. Đánh giá hiệu suất
Các nhà nghiên cứu đã đánh giá FastSwitch bằng cách sử dụng các mô hình LLaMA-8B và Qwen-32B trên các GPU như NVIDIA A10 và A100. Các kịch bản thử nghiệm bao gồm các cập nhật ưu tiên tần số cao và các cuộc hội thoại nhiều lượt được lấy từ bộ dữ liệu ShareGPT, trung bình 5,5 lượt mỗi cuộc hội thoại. FastSwitch đã vượt trội so với vLLM trên nhiều chỉ số khác nhau. Nó đạt được tốc độ tăng lên 4,3-5,8 lần ở P95 TTFT và 3,6-11,2 lần ở P99,9 TBT cho các mô hình và khối lượng công việc khác nhau. Hơn nữa, FastSwitch đã cải thiện thông lượng lên đến 1,44 lần, chứng minh khả năng xử lý khối lượng công việc phức tạp một cách hiệu quả. Hệ thống cũng đã giảm đáng kể chi phí chuyển đổi ngữ cảnh, cải thiện việc sử dụng I/O lên 1,3 lần và GPU lên 1,42 lần so với vLLM.
6. Kết luận
FastSwitch giải quyết những thiếu hiệu quả cơ bản trong việc phục vụ LLM bằng cách giới thiệu các tối ưu hóa sáng tạo cân bằng tính công bằng và hiệu quả. Việc giảm chi phí chuyển đổi ngữ cảnh và nâng cao việc sử dụng tài nguyên đảm bảo việc cung cấp dịch vụ chất lượng cao, khả năng mở rộng cho các môi trường đa người dùng. Những tiến bộ này làm cho nó trở thành một giải pháp chuyển đổi cho việc triển khai LLM hiện đại.
0 comments Blogger 0 Facebook
Đăng nhận xét