
Mục lục
- Giới thiệu
- Nền tảng cho việc phát triển và thử nghiệm LLM
- Tối ưu hóa tốc độ LLM mà không ảnh hưởng đến chất lượng
- Ảnh hưởng của kích thước mô hình lên tốc độ và hiệu suất LLM
- Hướng dẫn từng bước tích hợp và triển khai Llama 3.1-70B
- Mở rộng giới hạn suy luận LLM cho các ứng dụng AI
- Kết luận
1. Giới thiệu
Trong thế giới phát triển ứng dụng AI ngày nay, người dùng luôn mong đợi trải nghiệm nhanh chóng, thông minh và phản hồi tốt. Tuy nhiên, các mô hình ngôn ngữ lớn (LLM) thường chậm chạp trong việc phản hồi, gây ảnh hưởng không nhỏ đến trải nghiệm người dùng. Mỗi mili giây đều có giá trị!
Với các điểm cuối suy luận tốc độ cao của Cerebras, bạn có thể giảm thiểu độ trễ, tăng tốc độ phản hồi của mô hình và duy trì chất lượng ở quy mô lớn với các mô hình như Llama 3.1-70B. Chỉ với một vài bước đơn giản, bạn sẽ có thể tùy chỉnh và triển khai LLM của riêng mình, tối ưu hóa cả về tốc độ và chất lượng.
Trong bài viết này, chúng ta sẽ cùng nhau tìm hiểu cách:
- Thiết lập Llama 3.1-70B trong DataRobot LLM Playground.
- Tạo và áp dụng khóa API để tận dụng Cerebras cho suy luận.
- Tùy chỉnh và triển khai các ứng dụng thông minh, nhanh chóng hơn.
Đến cuối bài viết, bạn sẽ sẵn sàng triển khai các LLM mang lại tốc độ, độ chính xác và khả năng phản hồi thời gian thực.
2. Nền tảng cho việc phát triển và thử nghiệm LLM
Việc tạo mẫu và thử nghiệm các mô hình AI tạo sinh thường yêu cầu một loạt các công cụ rời rạc. Tuy nhiên, với một môi trường thống nhất, tích hợp cho LLM, các kỹ thuật truy xuất và các chỉ số đánh giá, bạn có thể chuyển từ ý tưởng đến nguyên mẫu làm việc nhanh hơn và ít rào cản hơn.
3. Tối ưu hóa tốc độ LLM mà không ảnh hưởng đến chất lượng
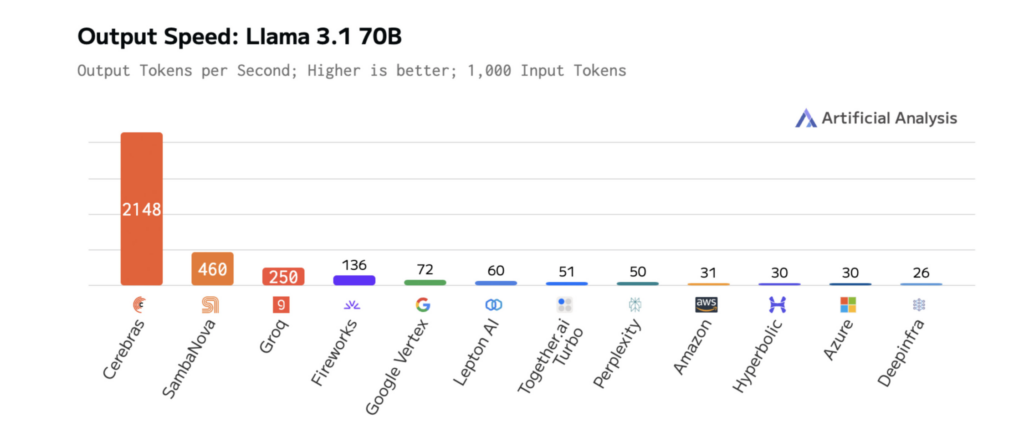
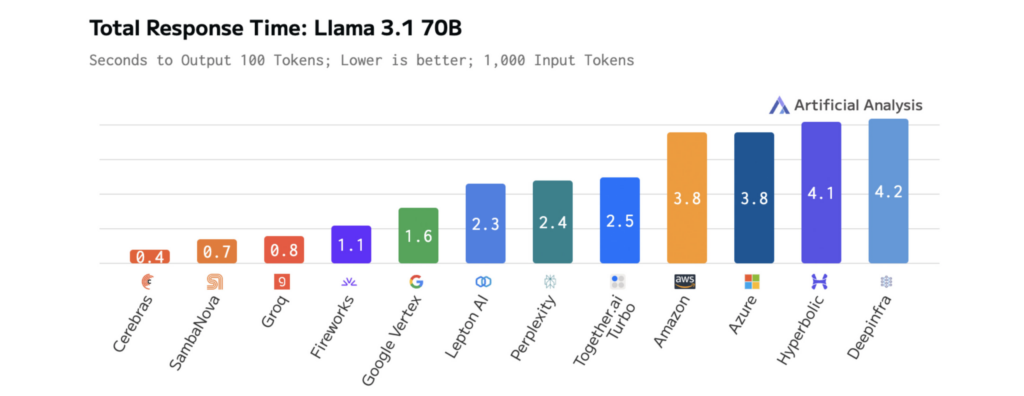
Độ trễ thấp là yếu tố cần thiết để xây dựng các ứng dụng AI nhanh chóng, phản hồi tốt. Tuy nhiên, tốc độ phản hồi tăng lên không nhất thiết phải đánh đổi bằng chất lượng. Cerebras Inference vượt trội hơn các nền tảng khác về tốc độ, cho phép các nhà phát triển xây dựng các ứng dụng mượt mà, phản hồi tốt và thông minh.
Khi kết hợp với trải nghiệm phát triển trực quan, bạn có thể:
- Giảm độ trễ LLM để tương tác người dùng nhanh hơn.
- Thử nghiệm hiệu quả hơn với các mô hình và quy trình mới.
- Triển khai các ứng dụng phản hồi tức thì với các hành động của người dùng.
Các biểu đồ dưới đây cho thấy hiệu suất của Cerebras trên Llama 3.1-70B, minh họa thời gian phản hồi nhanh hơn và độ trễ thấp hơn so với các nền tảng khác. Điều này cho phép lặp lại nhanh chóng trong quá trình phát triển và hiệu suất thời gian thực trong sản xuất.
4. Ảnh hưởng của kích thước mô hình lên tốc độ và hiệu suất LLM
Khi LLM ngày càng lớn hơn và phức tạp hơn, đầu ra của chúng trở nên phù hợp và toàn diện hơn — nhưng điều này đi kèm với một chi phí: tăng độ trễ. Cerebras giải quyết thách thức này bằng các phép tính tối ưu hóa, truyền dữ liệu hợp lý và giải mã thông minh được thiết kế để đạt tốc độ.
Những cải tiến về tốc độ này đã và đang thay đổi các ứng dụng AI trong các ngành như dược phẩm và AI giọng nói. Ví dụ:
- GlaxoSmithKline (GSK) sử dụng Cerebras Inference để tăng tốc độ khám phá thuốc, thúc đẩy năng suất cao hơn.
- LiveKit đã tăng hiệu suất của quy trình chế độ giọng nói của ChatGPT, đạt được thời gian phản hồi nhanh hơn so với các giải pháp suy luận truyền thống.
Kết quả là có thể đo lường được. Trên Llama 3.1-70B, Cerebras cung cấp khả năng suy luận nhanh hơn 70 lần so với GPU thông thường, cho phép tương tác thời gian thực mượt mà hơn và chu kỳ thử nghiệm nhanh hơn.
Hiệu suất này được cung cấp bởi Wafer-Scale Engine (WSE-3) thế hệ thứ ba của Cerebras, một bộ xử lý tùy chỉnh được thiết kế để tối ưu hóa các hoạt động đại số tuyến tính thưa thớt, dựa trên tensor, vốn là động lực của suy luận LLM.
Bằng cách ưu tiên hiệu suất, hiệu quả và tính linh hoạt, WSE-3 đảm bảo kết quả nhanh hơn, nhất quán hơn trong quá trình hoạt động của mô hình.
Tốc độ của Cerebras Inference làm giảm độ trễ của các ứng dụng AI được cung cấp bởi các mô hình của họ, cho phép suy luận sâu hơn và trải nghiệm người dùng nhạy bén hơn. Việc truy cập vào các mô hình được tối ưu hóa này rất đơn giản — chúng được lưu trữ trên Cerebras và có thể truy cập thông qua một điểm cuối duy nhất, vì vậy bạn có thể bắt đầu tận dụng chúng với thiết lập tối thiểu.

5. Hướng dẫn từng bước tích hợp và triển khai Llama 3.1-70B
Việc tích hợp LLM như Llama 3.1-70B từ Cerebras vào DataRobot cho phép bạn tùy chỉnh, thử nghiệm và triển khai các mô hình AI chỉ trong một vài bước. Quá trình này hỗ trợ phát triển nhanh hơn, thử nghiệm tương tác và kiểm soát tốt hơn việc tùy chỉnh LLM.
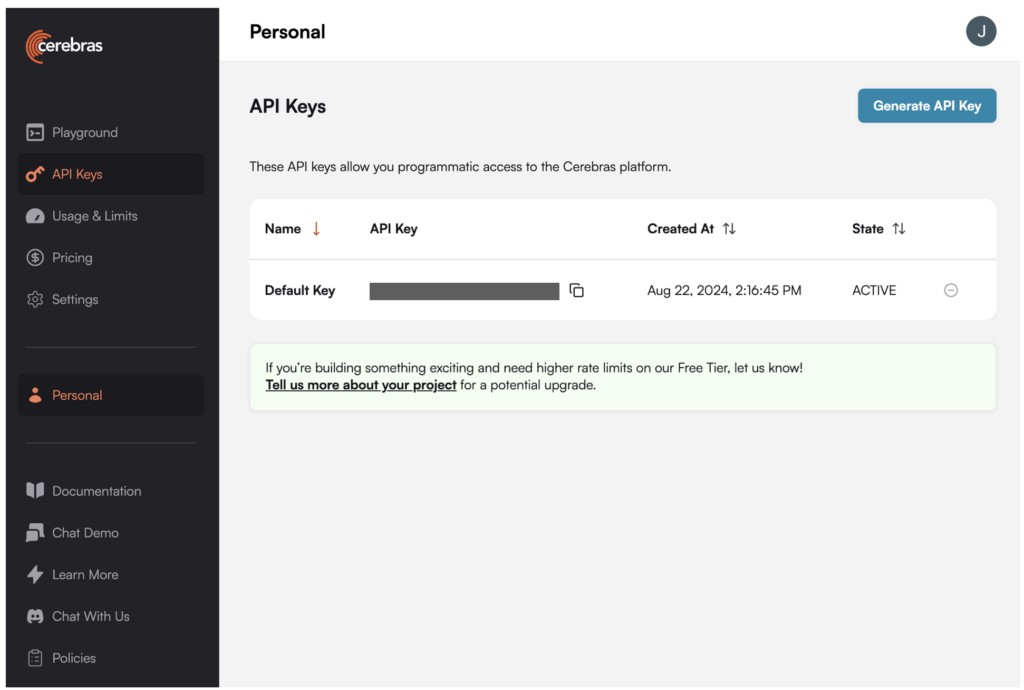
- Tạo khóa API cho Llama 3.1-70B trên nền tảng Cerebras.
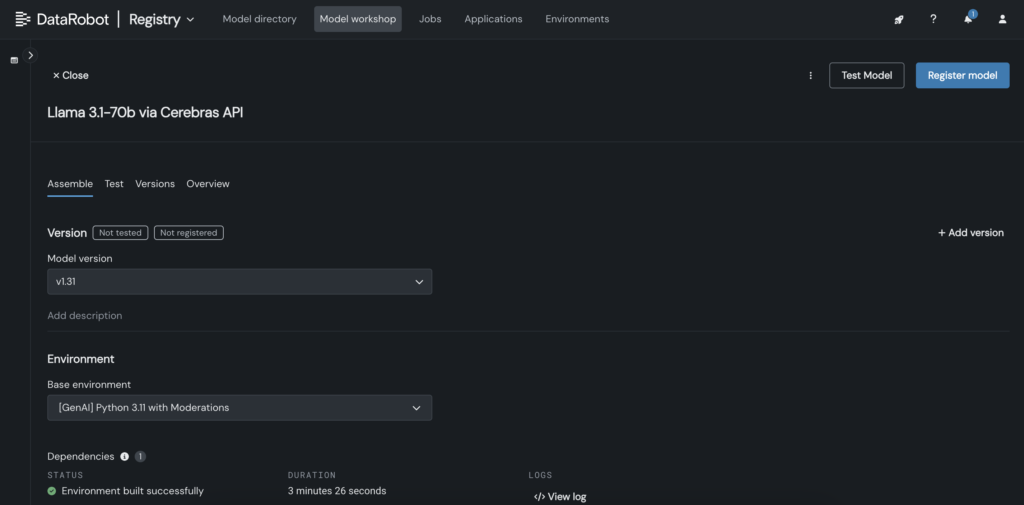
- Trong DataRobot, tạo mô hình tùy chỉnh trong Model Workshop gọi đến điểm cuối Cerebras nơi Llama 3.1 70B được lưu trữ.
- Trong mô hình tùy chỉnh, đặt khóa API Cerebras vào file custom.py.
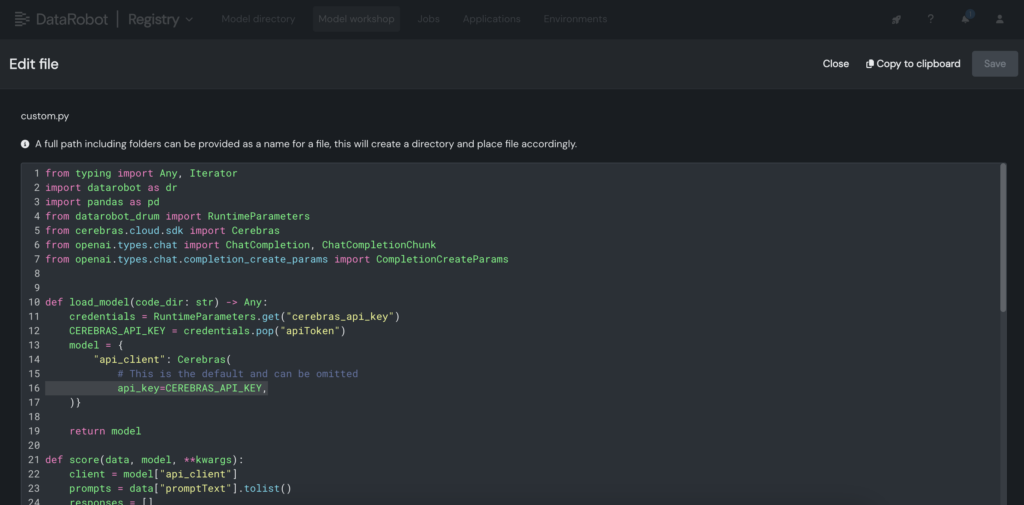
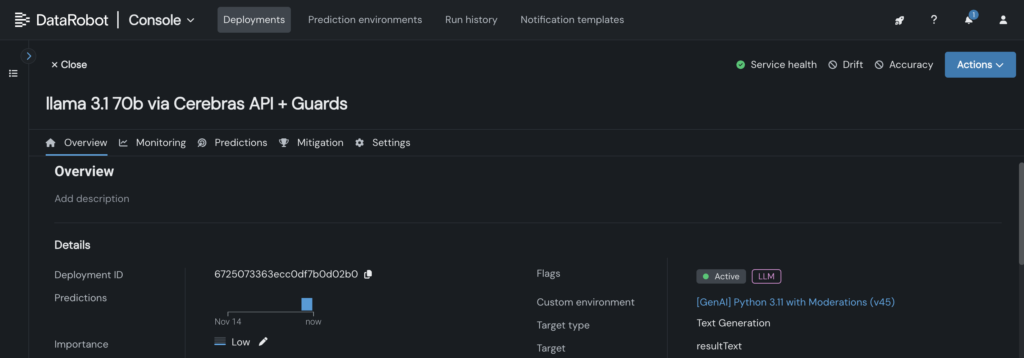
- Triển khai mô hình tùy chỉnh đến một điểm cuối trong DataRobot Console, cho phép các bản thiết kế LLM tận dụng nó cho suy luận.
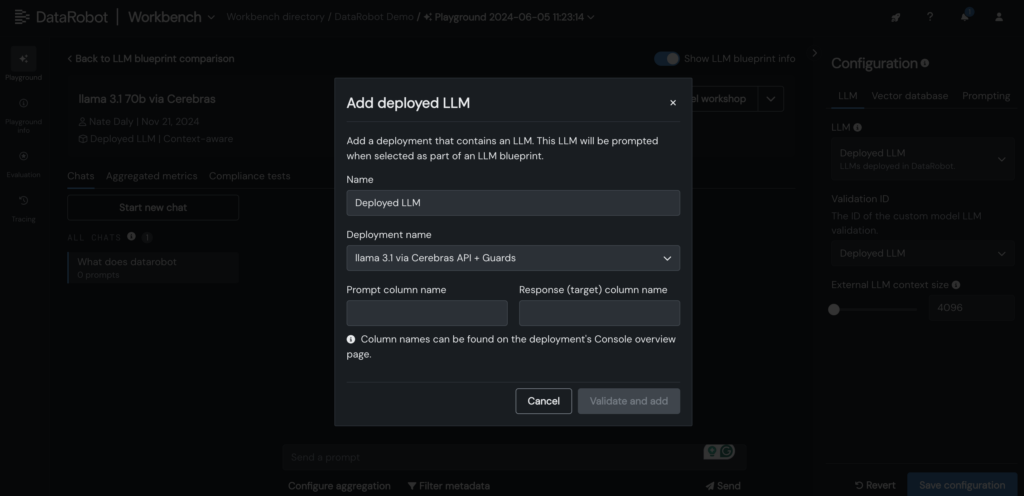
- Thêm LLM Cerebras đã triển khai vào bản thiết kế LLM trong DataRobot LLM Playground để bắt đầu trò chuyện với Llama 3.1 -70B.
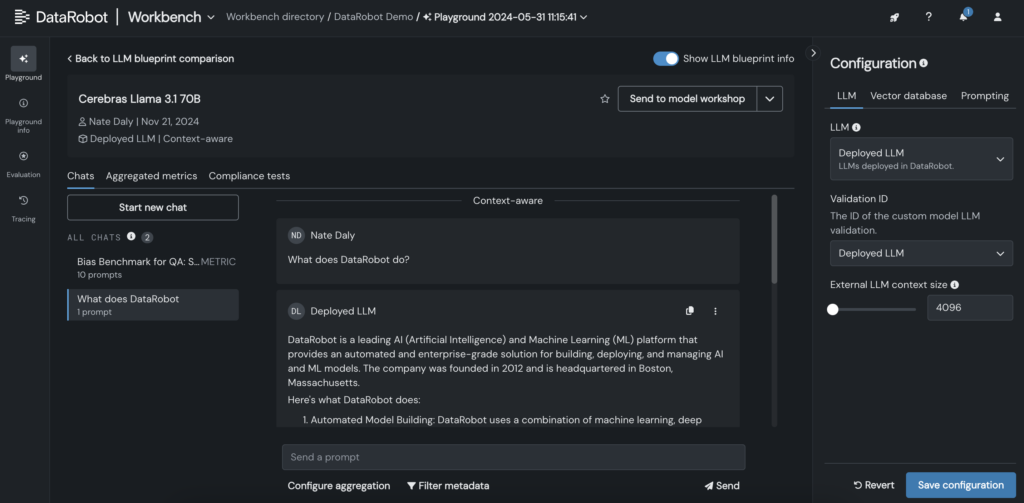
- Sau khi LLM được thêm vào bản thiết kế, hãy kiểm tra phản hồi bằng cách điều chỉnh các tham số nhắc và truy xuất, đồng thời so sánh đầu ra với các LLM khác trực tiếp trong giao diện DataRobot.
6. Mở rộng giới hạn suy luận LLM cho các ứng dụng AI
Triển khai các LLM như Llama 3.1-70B với độ trễ thấp và khả năng phản hồi thời gian thực không phải là một nhiệm vụ nhỏ. Tuy nhiên, với các công cụ và quy trình làm việc phù hợp, bạn có thể đạt được cả hai.
Bằng cách tích hợp LLM vào LLM Playground của DataRobot và tận dụng khả năng suy luận tối ưu hóa của Cerebras, bạn có thể đơn giản hóa việc tùy chỉnh, tăng tốc độ thử nghiệm và giảm độ phức tạp — đồng thời duy trì hiệu suất mà người dùng của bạn mong đợi.
Khi LLM ngày càng lớn hơn và mạnh mẽ hơn, việc có một quy trình hợp lý để thử nghiệm, tùy chỉnh và tích hợp sẽ là điều cần thiết cho các nhóm muốn dẫn đầu.
7. Kết luận
Hãy tự mình khám phá. Truy cập Cerebras Inference, tạo khóa API và bắt đầu xây dựng ứng dụng AI trong DataRobot.
0 comments Blogger 0 Facebook
Đăng nhận xét