
Mục lục
- Giới thiệu
- Phương pháp nghiên cứu
- Kết quả
- Thảo luận
- Kết luận
1. Giới thiệu
Trong những năm gần đây, các mô hình ngôn ngữ lớn (LLM) – hệ thống trí tuệ nhân tạo (AI) được huấn luyện trên các thuật toán học sâu – đã phát triển đáng kể và trở nên ngày càng tinh vi. Các hệ thống AI này, như GPT-4 Turbo của OpenAI (San Francisco, CA) và LLaMA 3.1 của Meta (Menlo Park, CA), sử dụng các kỹ thuật để tạo ra phản hồi văn bản giống như con người [1, 2]. Sự phát triển nhanh chóng của chúng đã biến đổi nhiều ngành công nghiệp, cho phép thực hiện các nhiệm vụ như giải quyết vấn đề chẩn đoán, dịch ngôn ngữ và đưa ra các đề xuất cá nhân hóa, thể hiện tiềm năng của AI trong tương lai.
Cụ thể, LLM như GPT-4 Turbo và LLaMA 3.1, đều được phát hành vào năm 2023, cho đến nay đã là nền tảng của tiềm năng này [1-3]. Mỗi mô hình sử dụng các phân tích học sâu tương tự dựa trên các tập dữ liệu rộng lớn, hoàn thành nhiều nhiệm vụ đa dạng, từ tạo văn bản đơn giản đến lập luận phức tạp. GPT-4 Turbo, một phiên bản nâng cao của GPT-4.0, GPT-3.5 và GPT-3.0, tự phân biệt mình bằng "cửa sổ ngữ cảnh" được cải thiện, có nghĩa là nó có khả năng ghi nhớ và xử lý nhiều trang đầu vào hơn để tạo ra đầu ra phức tạp hơn so với các thế hệ trước [1, 4]. Mặc dù tương tự, LLaMA 3.1 của Meta được biết đến nhiều hơn với hiệu quả và tối ưu hóa hiệu suất, trong khi GPT-4 Turbo được biết đến với khả năng xử lý lớn hơn và xử lý nhiệm vụ đa phương thức [2, 4, 5].
Nghiên cứu này nhằm mục đích so sánh các mô hình này trong một tập hợp câu hỏi chẩn đoán hình ảnh nhi khoa, đánh giá khả năng của chúng trong việc trả lời chính xác các câu hỏi chuyên ngành. Cuối cùng, phân tích này hy vọng sẽ làm rõ thế mạnh và các lĩnh vực tiềm năng cần cải thiện của mỗi mô hình trong giáo dục y tế.
2. Phương pháp nghiên cứu
Nghiên cứu này so sánh độ chính xác của ChatGPT-4 Turbo và LLaMA 3.1 của Meta bằng cách đánh giá phản hồi của chúng đối với 79 câu hỏi văn bản từ sách giáo khoa "Pediatric Imaging: A Core Review" [6]. Mục tiêu chính là đánh giá độ chính xác tổng thể với mục tiêu thứ cấp là phân tích hiệu suất của mỗi mô hình AI trong các phần cụ thể. Từ nhóm câu hỏi ban đầu gồm 302 câu hỏi của cuốn sách, 79 câu hỏi đã được chọn dựa trên các tiêu chí đã xác định, loại trừ các câu hỏi dựa trên hình ảnh. Các câu hỏi được chia thành bảy phần, tương ứng với các trọng tâm khác nhau của văn bản như chụp X-quang cơ xương và ngực, với 38 câu hỏi được sửa đổi nhẹ để duy trì tính nhất quán của định dạng chỉ có văn bản.
Độ chính xác của mỗi LLM được đo bằng cách tính tỷ lệ phần trăm câu trả lời đúng cho mỗi mô hình trên toàn bộ tập hợp câu hỏi cũng như trong các phần. Mỗi mô hình được định hướng để chờ đợi một loạt câu hỏi trắc nghiệm và cẩn thận chọn những gì chúng phân tích là câu trả lời đúng (Hình 1). Sử dụng hệ thống trả lời nhị phân, các câu hỏi được trả lời đúng được ghi chú riêng là "1" và không đúng là "0", và phân tích cuối cùng sử dụng tổng của các ghi chú riêng lẻ. Phân tích hiệu suất của mỗi mô hình cho phép nghiên cứu này làm nổi bật bất kỳ sự khác biệt nào về độ chính xác, cả tổng thể và trong các phần (Hình 2). Phương pháp này cho phép so sánh rõ ràng cách GPT-4 Turbo và LLaMA 3.1 xử lý các câu hỏi về chẩn đoán hình ảnh nhi khoa. Nghiên cứu này không yêu cầu sự chấp thuận của Hội đồng Đánh giá Quy trình Nghiên cứu (IRB) do thiếu dữ liệu bệnh nhân có liên quan, và tất cả dữ liệu đã được kiểm tra chéo về độ chính xác chẩn đoán.
3. Kết quả
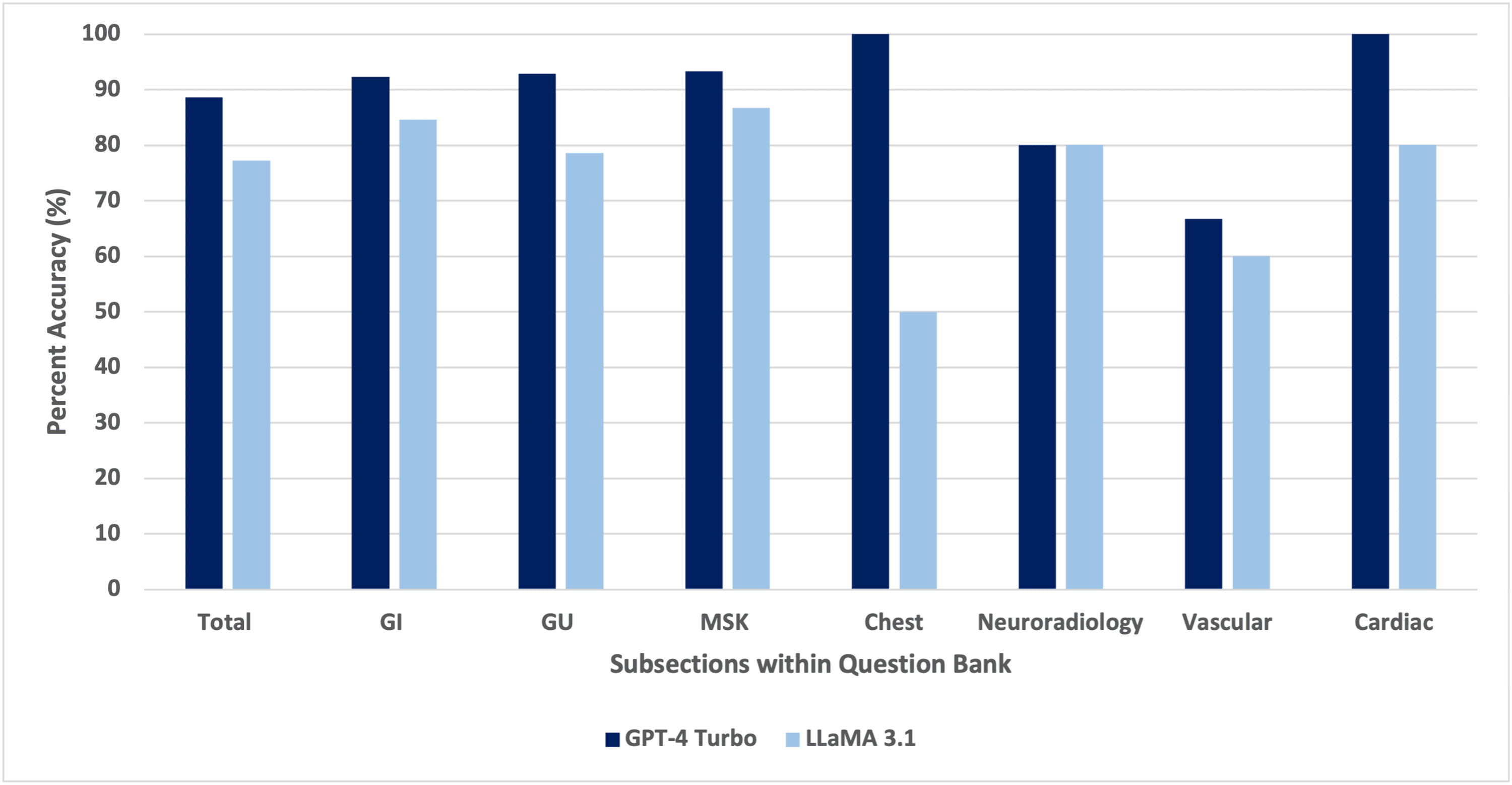
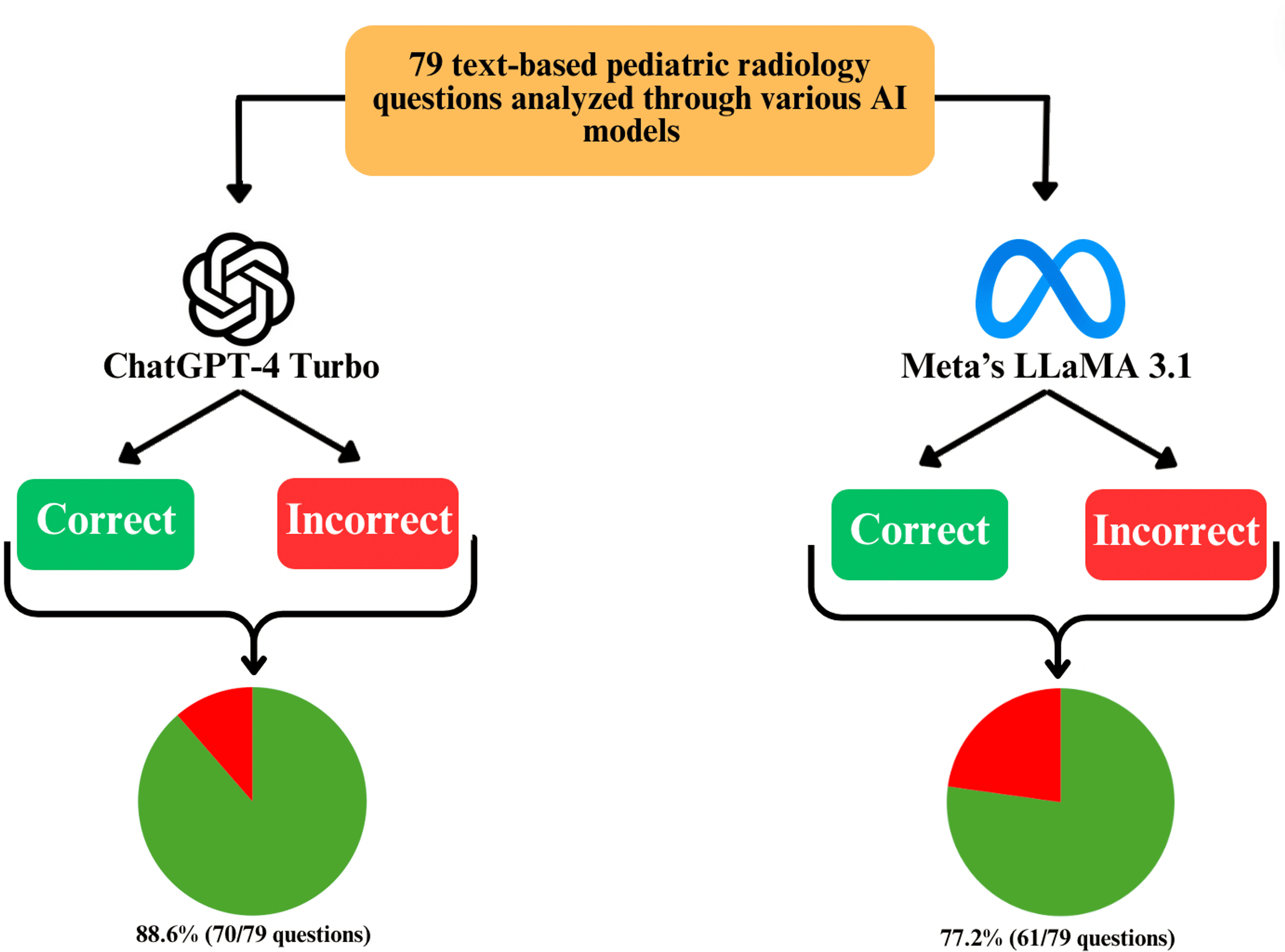
Trong phân tích này, GPT-4 Turbo đã chứng minh độ chính xác tổng thể cao hơn so với LLaMA 3.1 của Meta. GPT-4 Turbo đã trả lời đúng 88,6% trong số 79 câu hỏi (70/79), trong khi LLaMA 3.1 đã trả lời đúng 77,2% (61/79). Khi kết quả được chia nhỏ hơn nữa thành các phần, GPT-4 Turbo liên tục vượt trội hơn LLaMA 3.1 ở hầu hết các lĩnh vực (Hình 3, 4).

GPT-4 Turbo đạt 92,3% (12/13) trong hệ thống tiêu hóa, 92,9% (13/14) trong hệ thống tiết niệu, 93,3% (14/15) trong hệ thống cơ xương, 100% (2/2) trong chụp X-quang ngực, 80,0% (4/5) trong thần kinh sọ não, 66,7% (10/15) trong mạch máu và 100% (15/15) trong tim mạch. Để so sánh, LLaMA 3.1 đạt 84,6% (11/13) trong hệ thống tiêu hóa, 78,6% (11/14) trong hệ thống tiết niệu, 86,7% (13/15) trong hệ thống cơ xương, 50% (1/2) trong chụp X-quang ngực, 80,0% (4/5) trong thần kinh sọ não, 60,0% (9/15) trong mạch máu và 80,0% (12/15) trong tim mạch (Bảng 1).
| Số lượng câu hỏi | Tỷ lệ chính xác của GPT4-Turbo (%) | Số lượng câu hỏi, đúng/tổng | Tỷ lệ chính xác của LLaMA 3.1 (%) | Số lượng câu hỏi, đúng/tổng |
|---|---|---|---|---|
| Tổng thể | 79 | 88,6% | 70/79 | 77,2% |
| Tiêu hóa | 13 | 92,3% | 12/13 | 84,6% |
| Tiết niệu | 14 | 92,3% | 13/14 | 78,6% |
| Cơ xương | 15 | 93,3% | 14/15 | 86,7% |
| Ngực | 2 | 100,0% | 2/2 | 50,0% |
| Thần kinh sọ não | 5 | 80,0% | 4/5 | 80,0% |
| Mạch máu | 15 | 66,7% | 10/15 | 60,0% |
| Tim mạch | 15 | 100,0% | 15/15 | 80,0% |
Bảng 1: So sánh tỷ lệ phần trăm chính xác giữa ChatGPT-4 Turbo và LLaMA 3.1. GI: tiêu hóa; GU: tiết niệu; MSK: cơ xương.
Về độ chính xác cụ thể theo từng phần, GPT-4 Turbo hoạt động tốt nhất trong chụp X-quang ngực và tim mạch (100,0%), tiếp theo là hệ thống cơ xương (93,3%), hệ thống tiêu hóa (92,3%) và hệ thống tiết niệu (92,9%). Hiệu suất thấp nhất của GPT-4 Turbo là trong mạch máu, ở mức 66,7%. Độ chính xác cao nhất của LLaMA 3.1 là trong hệ thống cơ xương (86,7%), và thấp nhất là trong chụp X-quang ngực (50,0%).
4. Thảo luận
Hiệu suất tổng thể & từng phần của mỗi mô hình AI
Tỷ lệ phần trăm chính xác cao hơn của GPT-4 Turbo so với LLaMA 3.1 ban đầu ngụ ý khả năng xử lý tốt hơn các câu hỏi dựa trên văn bản. Hiệu suất này có thể là do việc huấn luyện trên các tập dữ liệu lớn hơn, chuyên ngành hơn, được trang bị tốt hơn để trả lời các câu hỏi cụ thể, không giống như LLaMA 3.1, được phát triển để xử lý trọng tâm nghiên cứu rộng hơn với hiệu quả cao hơn [1, 6]. Như đã nêu trước đó, cửa sổ ngữ cảnh lớn hơn của GPT-4 Turbo, giúp tăng cường khả năng giải quyết vấn đề phức tạp, có thể tăng cường khả năng xử lý các câu hỏi phức tạp [1, 2].
Điều đáng chú ý là tỷ lệ phần trăm chính xác tương tự trong các danh mục nhỏ hơn như thần kinh sọ não và mạch máu có thể là do số lượng câu hỏi dựa trên văn bản hạn chế so với các phần lớn hơn. Việc nghiên cứu loại trừ các câu hỏi dựa trên hình ảnh, không phản ánh đánh giá thực tế về chẩn đoán hình ảnh, có thể đã hạn chế phạm vi nghiên cứu của chúng tôi.
Thế mạnh và hạn chế chung của AI trong y học
AI cung cấp các công cụ và tích hợp cơ sở dữ liệu ngày càng phát triển của nó, tiếp tục xử lý dữ liệu nhanh hơn và đôi khi chính xác hơn con người [6, 7]. Trong các lĩnh vực y tế cụ thể, chẳng hạn như chẩn đoán hình ảnh, các LLM này có tiềm năng giúp nhanh chóng diễn giải tài liệu về tình trạng bệnh nhân, tóm tắt tiền sử bệnh nhân hoặc tạo báo cáo. Trên thực tế, các nghiên cứu so sánh trước đây giữa các phiên bản trước đó của các LLM này đã tìm thấy sự khác biệt đáng kể về độ chính xác tổng thể, điều này có thể là sản phẩm phụ của chức năng dự định của mỗi LLM [8-10]. Tuy nhiên, vẫn còn những lo ngại về khả năng của các mô hình này trong việc diễn giải và phân tích chính xác hình ảnh hoặc cung cấp thông tin chính xác, đặc biệt là với các sự kiện được báo cáo trong quá khứ về phân tích không chính xác [7, 11]. Mặc dù sự phát triển của các mô hình này rất nhanh chóng, nhưng việc tích hợp của chúng vào hầu hết các hệ thống vẫn đang trong giai đoạn phát triển, và các phân tích như nghiên cứu này tiếp tục đánh dấu khả năng ngày càng phát triển và tiềm năng của nó cho tương lai.
Một điều thú vị giữa GPT-4 Turbo và LLaMA 3.1 của Meta là sự khác biệt giữa phần mềm nguồn mở và các mô hình độc quyền [1]. Hiện tại, LLaMA được gắn nhãn là nguồn mở, cho phép các nhà phát triển tự do tạo hoặc thử nghiệm với thế mạnh và hạn chế của mô hình. Tuy nhiên, GPT-4 Turbo được gắn nhãn là mô hình "độc quyền", nhắm đến mục đích thương mại [1]. Khách hàng vẫn được phép sử dụng các công cụ và cơ sở dữ liệu của nó, nhưng điều này hạn chế khả năng thử nghiệm so với LLaMA [1, 4]. Sự phân biệt giữa các mô hình này có thể là một điểm bàn luận trong tương lai nếu một mô hình trở nên dễ tiếp cận hơn để thay đổi, chẳng hạn như trong các lĩnh vực phát triển nhanh chóng như y học.
Nhận thức của công chúng và sự tin tưởng vào AI trong chăm sóc sức khỏe
Việc xem xét về mặt đạo đức việc sử dụng AI trong các lĩnh vực chăm sóc sức khỏe là phức tạp và có sự giao thoa đáng kể với nhận thức của công chúng về AI nói chung. Rõ ràng là có sự phấn khích ngày càng tăng đối với tương lai của các LLM này trong nhiều lĩnh vực, và nhiều người nhìn nhận các mô hình này với sự lạc quan rằng chúng có thể cải thiện tốc độ của nhiều nhiệm vụ và giảm lỗi của con người [12, 13]. Tuy nhiên, các vấn đề phát sinh xung quanh độ chính xác và tính chấp nhận được của việc ra quyết định của AI, đặc biệt là khi được sử dụng trong các tình huống khẩn cấp hoặc cho rằng một số mô hình chỉ được đào tạo trên các tập dữ liệu hạn chế [12-14]. Cụ thể trong y học, nhiều nghiên cứu báo cáo rằng bệnh nhân tìm kiếm sự tin tưởng trong phán đoán của họ về các mô hình AI và các mô hình này hiện chưa đạt đến mức đó [13-16]. Sự khác biệt này được ghi nhận thêm trong nghiên cứu này, nơi các mô hình AI khác nhau được cho là có hiệu suất khác nhau trong cùng một tập hợp câu hỏi, nhấn mạnh thêm sự thiếu huấn luyện tiêu chuẩn hóa trên các mô hình [16, 17]. Mỗi mô hình này được đào tạo với các nhiệm vụ cụ thể và trong khi chúng sẽ tiếp tục cải thiện trong nhiều thập kỷ, việc huấn luyện rộng rãi của chúng vẫn chưa được phát triển trong các lĩnh vực đòi hỏi độ chính xác cao, chẳng hạn như chẩn đoán hình ảnh.
5. Kết luận
Những phát hiện của nghiên cứu này phản ánh tỷ lệ phần trăm chính xác cao hơn với GPT-4 Turbo so với LLaMA 3.1 trong việc trả lời một tập hợp các câu hỏi tiêu chuẩn về chẩn đoán hình ảnh nhi khoa, với GPT-4 Turbo đạt 88,6% chính xác (70/79) so với 77,2% của LLaMA 3.1 (61/79). Những dữ liệu này cho thấy GPT-4 Turbo có thể có một tập dữ liệu được cải thiện để xử lý các nhiệm vụ dựa trên văn bản chuyên ngành. Tuy nhiên, sự khác biệt giữa các phần khác nhau, chẳng hạn như thần kinh sọ não, là tối thiểu, và ý nghĩa thống kê không được đánh giá tương đương. Những phát hiện này nhấn mạnh sự cần thiết phải diễn giải thận trọng dữ liệu và cho thấy cả hai mô hình đều có những thế mạnh và hạn chế riêng cần được xem xét khi tích hợp AI trong nhiều thiết lập.
Tóm lại, nghiên cứu này nhấn mạnh tiềm năng của các mô hình AI trong giáo dục y tế, đặc biệt là trong các lĩnh vực chuyên ngành như chẩn đoán hình ảnh, nơi việc diễn giải hình ảnh chính xác là rất quan trọng. Khi AI tiếp tục phát triển, nó mang đến tiềm năng thú vị cho y học, chẩn đoán hình ảnh và kết quả tổng thể cho bệnh nhân. Tuy nhiên, điều quan trọng là các mô hình này được sử dụng một cách có đạo đức và như là một sự bổ sung cho chuyên môn của con người. Nghiên cứu trong tương lai nên tiếp tục điều tra các mô hình này để tối ưu hóa AI đồng thời duy trì việc áp dụng có trách nhiệm của nó.
0 comments Blogger 0 Facebook
Đăng nhận xét